0. Data Structure
| Subject | Block | Trial | L_choice | R_choice | L_reward | R_reward | Sub_Choose | - |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | A | B | 36 | 40 | A | … |
| 1 | 1 | 2 | B | A | 0 | 36 | B | … |
| 1 | 1 | 3 | C | D | -36 | -40 | C | … |
| 1 | 1 | 4 | D | C | 0 | -36 | D | … |
| … | … | … | … | … | … | … | … | … |
data = multiRL::TAB
colnames = list(
subid = "Subject", block = "Block", trial = "Trial",
object = c("L_choice", "R_choice"),
reward = c("L_reward", "R_reward"),
action = "Sub_Choose",
exinfo = c("...", "...", "...")
)
behrule = list(
cue = c("A", "B", "C", "D"),
rsp = c("A", "B", "C", "D")
)Note
- The number of
objectandrewardcan be multiple (> 2), but they must have a strict one-to-one correspondence.
- An object can consist of multiple elements; please separate them
with “_” (e.g., ‘context_target_behavior’).
- An action can point to either an entire object or a specific part of
it. For details, see this
- Any additional information (column names) should be passed to
exinfoas a character vector.
1. Run Model
Create a function with ONLY ONE argument,
params
Model <- function(params){
############################# [Modify Here] ####################################
params <- list(free = list(alpha = params[1], beta = params[2]))
############################# [Modify Here] ####################################
multiRL.model <- multiRL::run_m(
data = data,
behrule = behrule,
colnames = colnames,
params = params,
funcs = funcs,
priors = priors,
settings = settings
)
assign(x = "multiRL.model", value = multiRL.model, envir = multiRL.env)
return(.return_result(multiRL.model))
}How to define a new model?
- Customize the following six core functions.
- Figure out the free parameters within your model.
- Declare these parameters as free when defining the object function above.
Learning Rate (α)
print(multiRL::func_alpha)
func_alpha <- function(
shown,
is.fp,
qvalue,
reward,
utility,
system,
rownum,
params,
hidden,
...
){
list2env(list(...), envir = environment())
# If you need extra information(...)
# Column names may be lost(C++), indexes are recommended
# e.g.
# Trial <- idinfo[3]
# Frame <- exinfo[1]
# Action <- behave[1]
Q0 <- params[["Q0"]]
alpha <- params[["alpha"]]
alphaN <- params[["alphaN"]]
alphaP <- params[["alphaP"]]
if (is.nan(Q0) && is.fp) {
update <- utility
hidden[1] <- "first"
return(list(output = update, hidden = hidden))
}
# Determine the model currently in use based on which parameters are free.
if (
system == "RL" && !(is.null(alpha)) && is.null(alphaN) && is.null(alphaP)
) {
model <- "TD"
} else if (
system == "RL" && is.null(alpha) && !(is.null(alphaN)) && !(is.null(alphaP))
) {
model <- "RSTD"
} else if (
system == "WM"
) {
model <- "WM"
} else {
stop("Unknown Model! Plase modify your learning rate function")
}
# TD
if (model == "TD") {
update <- qvalue + alpha * (utility - qvalue)
# RSTD
} else if (model == "RSTD" && utility < qvalue) {
update <- qvalue + alphaN * (utility - qvalue)
} else if (model == "RSTD" && utility >= qvalue) {
update <- qvalue + alphaP * (utility - qvalue)
# WM
} else if (model == "WM") {
update <- reward
}
hidden[1] <- "alpha"
return(list(output = update, hidden = hidden))
}Probability Function (β)
func_beta <- function(
shown,
qvalue,
explor,
rownum,
params,
hidden,
system,
...
){
list2env(list(...), envir = environment())
# If you need extra information(...)
# Column names may be lost(C++), indexes are recommended
# e.g.
# Trial <- idinfo[3]
# Frame <- exinfo[1]
# Action <- behave[1]
beta <- params[["beta"]]
lapse <- params[["lapse"]]
weight <- params[["weight"]]
capacity <- params[["capacity"]]
index <- which(!is.na(qvalue[[1]]))
n_shown <- length(index)
n_system <- length(qvalue)
n_options <- length(qvalue[[1]])
# Assign weights to different systems
if (length(weight) == 1L) {weight <- c(weight, 1 - weight)}
weight <- weight / sum(weight)
if (n_system == 1) {weight <- weight[1]}
# Compute the probabilities estimated by different systems
prob_mat <- matrix(0, nrow = n_options, ncol = n_system)
if (explor == 1) {
prob_mat[index, ] <- 1 / n_shown
prob_mat[prob_mat == 0] <- NA
} else {
for (s in seq_len(n_system)) {
sub_qvalue <- qvalue[[s]]
exp_stable <- exp(beta * (sub_qvalue - max(sub_qvalue, na.rm = TRUE)))
prob_mat[, s] <- exp_stable / sum(exp_stable, na.rm = TRUE)
}
}
# Weighted average
prob <- as.vector(prob_mat %*% weight)
# lapse
prob <- (1 - lapse * n_shown) * prob + lapse
hidden[2] <- "beta"
return(list(output = prob, hidden = hidden))
}Utility Function (γ)
print(multiRL::func_gamma)
func_gamma <- function(
shown,
reward,
rownum,
params,
hidden,
...
){
list2env(list(...), envir = environment())
# If you need extra information(...)
# Column names may be lost(C++), indexes are recommended
# e.g.
# Trial <- idinfo[3]
# Frame <- exinfo[1]
# Action <- behave[1]
gamma <- params[["gamma"]]
# Stevens' Power Law
utility <- ((reward >= 0) * 2 - 1) * (abs(reward) ^ gamma)
hidden[3] <- "gamma"
return(list(output = utility, hidden = hidden))
}Bias Function (δ)
print(multiRL::func_delta)
func_delta <- function(
shown,
count,
rownum,
params,
hidden,
...
){
list2env(list(...), envir = environment())
# If you need extra information(...)
# Column names may be lost(C++), indexes are recommended
# e.g.
# Trial <- idinfo[3]
# Frame <- exinfo[1]
# Action <- behave[1]
# Sticky to the same latent
latent <- behave[2]
if (is.na(latent)) {
last_latent <- shown * 0
} else {
last_latent <- as.numeric(!is.na(shown)) * as.numeric(cue %in% latent)
}
# Sticky to the same action(simulation)
simulation <- behave[3]
if (is.na(simulation)) {
last_simulation <- shown * 0
} else {
last_simulation <- as.numeric(
rowSums(state[shown, , drop = FALSE] == simulation) > 0
)
}
# Sticky to the same position
position <- behave[4]
if (is.na(position)) {
last_position <- shown * 0
} else {
last_position <- as.numeric(shown == as.numeric(position))
}
delta <- params[["delta"]]
sticky <- params[["sticky"]]
# Upper-Confidence-Bound
bias <- delta * sqrt(log(count + exp(1)) / (count + 1e-10)) +
# Sticky to the same latent
sticky * last_latent +
# Sticky to the same action(simulation)
sticky * last_simulation +
# Sticky to the same position
sticky * last_position
hidden[4] <- "delta"
return(list(output = bias, hidden = hidden))
}Exploration Function (ε)
print(multiRL::func_epsilon)
func_epsilon <- function(
shown,
rownum,
params,
hidden,
...
){
list2env(list(...), envir = environment())
# If you need extra information(...)
# Column names may be lost(C++), indexes are recommended
# e.g.
# Trial <- idinfo[3]
# Frame <- exinfo[1]
# Action <- behave[1]
epsilon <- params[["epsilon"]]
threshold <- params[["threshold"]]
# Determine the model currently in use based on which parameters are free.
if (is.na(epsilon) && threshold > 0) {
model <- "first"
} else if (!(is.na(epsilon)) && threshold == 0) {
model <- "decreasing"
} else if (!(is.na(epsilon)) && threshold == 1) {
model <- "greedy"
} else {
stop("Unknown Model! Plase modify your learning rate function")
}
set.seed(rownum)
# Epsilon-First:
if (rownum <= threshold) {
try <- 1
} else if (rownum > threshold && model == "first") {
try <- 0
# Epsilon-Greedy:
} else if (rownum > threshold && model == "greedy"){
try <- as.integer(stats::runif(1) < epsilon)
# Epsilon-Decreasing:
} else if (rownum > threshold && model == "decreasing") {
prob_explore <- 1 / (1 + epsilon * rownum)
try <- as.integer(stats::runif(1) < prob_explore)
}
hidden[5] <- "epsilon"
return(list(output = try, hidden = hidden))
}Decay Rate (ζ)
func_zeta <- function(
shown,
value0,
values,
reward,
utility,
system,
rownum,
params,
hidden,
...
){
list2env(list(...), envir = environment())
# If you need extra information(...)
# Column names may be lost(C++), indexes are recommended
# e.g.
# Trial <- idinfo[3]
# Frame <- exinfo[1]
# Action <- behave[1]
zeta <- params[["zeta"]]
bonus <- params[["bonus"]]
if (reward == 0) {
decay <- values + zeta * (value0 - values)
} else if (reward < 0) {
decay <- values + zeta * (value0 - values) + bonus
} else if (reward > 0) {
decay <- values + zeta * (value0 - values) - bonus
}
hidden[6] <- "zeta"
return(list(output = decay, hidden = hidden))
}2. Recovery
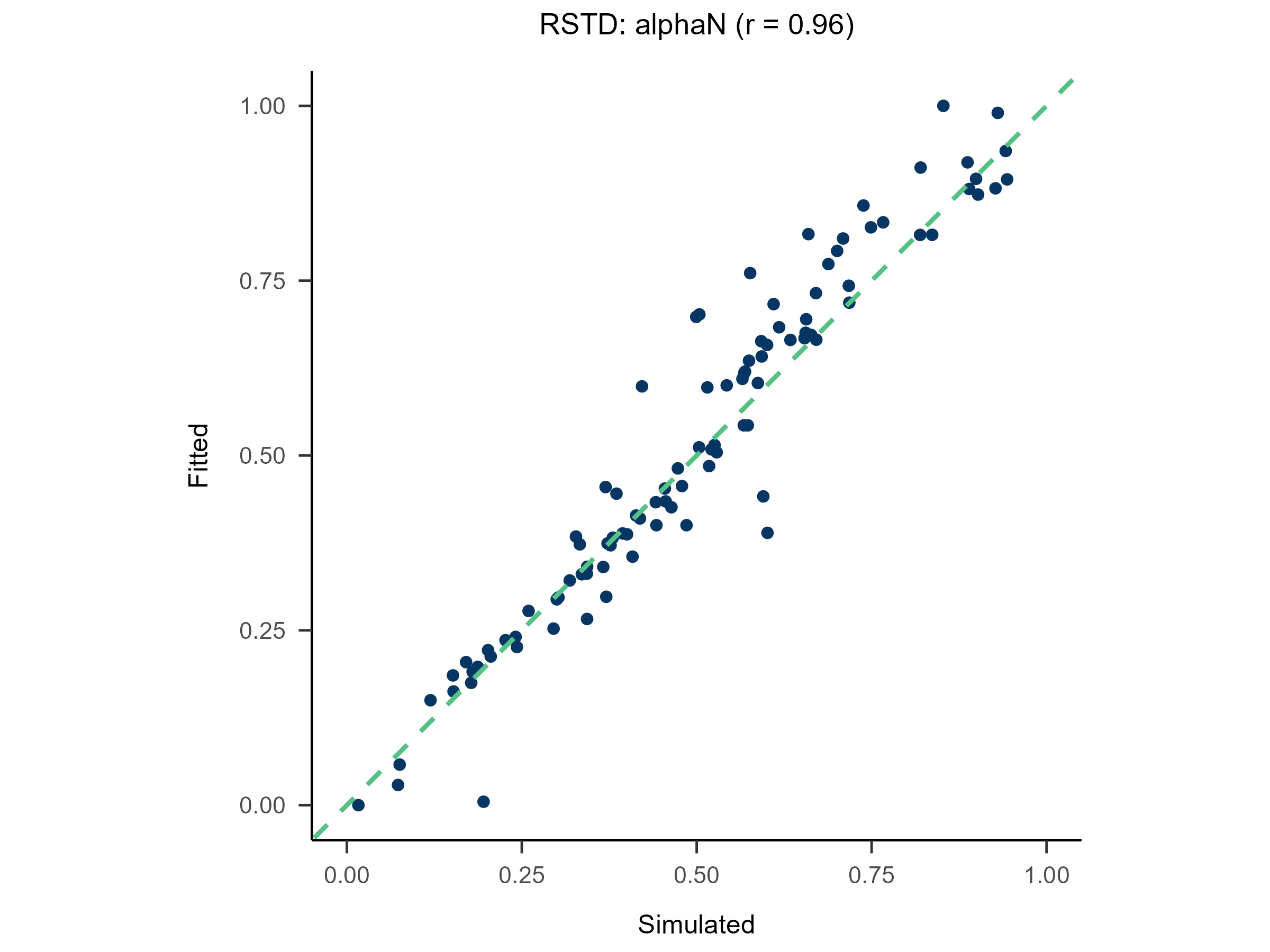
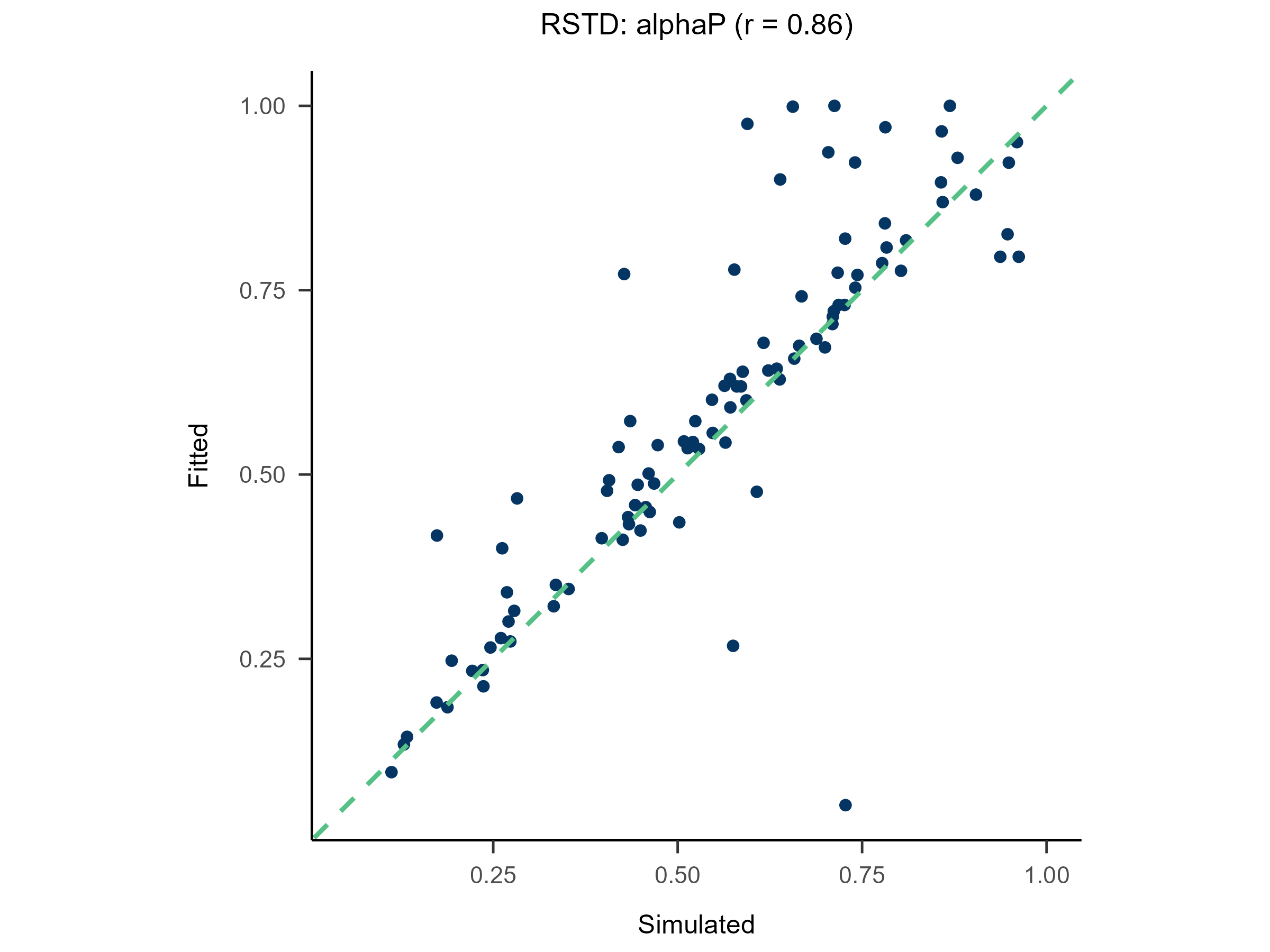
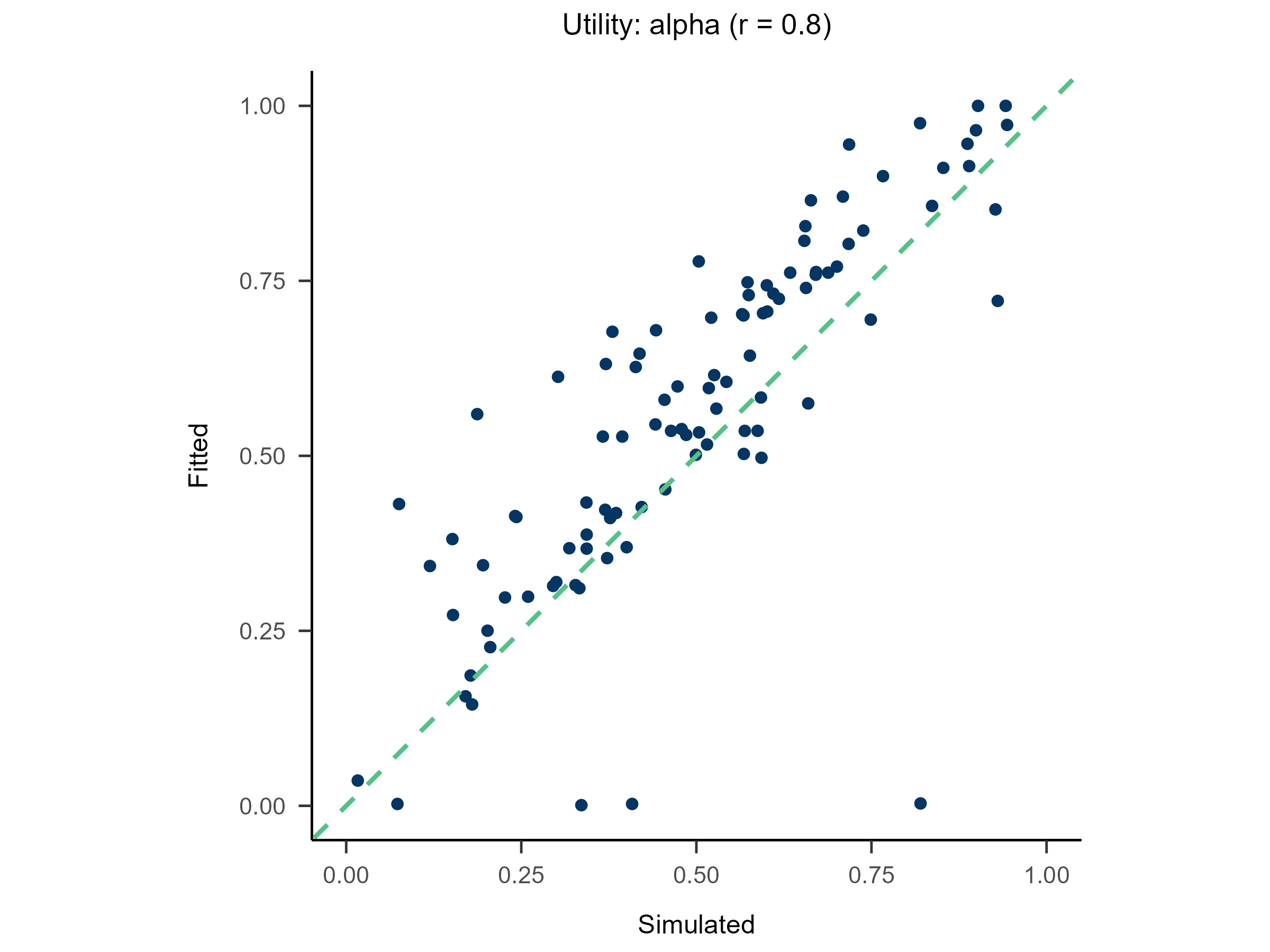
Randomly generate free parameters for Model A and use them to produce simulated data. Subsequently, fit all candidate models to this simulated data. This step involves parameter recovery and model recovery for each candidate model. If a model meets the following two criteria, it can be considered robust and suitable for fitting real data and for model comparison.
- If Model A can successfully recover its true generative parameters from the simulated data, it indicates strong parameter recovery for the model.
- If Model A yields the best fit indices compared to all other candidate models when fitted to the data it generated, it demonstrates robust model recovery.
Note
if a researcher skips this step and directly fits the candidate models to real data and conducts model comparison, then when one model emerges as the winner, it is impossible to determine whether this is because the model is genuinely superior or because the other models are not robust at all and thus are not even qualified to be included in a model comparison.
recovery.MLE <- multiRL::rcv_d(
estimate = "MLE",
data = data,
colnames = colnames,
behrule = behrule,
models = list(multiRL::TD, multiRL::RSTD, multiRL::Utility),
priors = list(
list(
alpha = function(x) {stats::rbeta(n = 1, shape1 = 2, shape2 = 2)},
beta = function(x) {stats::rexp(n = 1, rate = 1)}
),
list(
alphaN = function(x) {stats::rbeta(n = 1, shape1 = 2, shape2 = 2)},
alphaP = function(x) {stats::rbeta(n = 1, shape1 = 2, shape2 = 2)},
beta = function(x) {stats::rexp(n = 1, rate = 1)}
),
list(
alpha = function(x) {stats::rbeta(n = 1, shape1 = 2, shape2 = 2)},
beta = function(x) {stats::rexp(n = 1, rate = 1)},
gamma = function(x) {stats::rbeta(n = 1, shape1 = 2, shape2 = 2)}
)
),
settings = list(name = c("TD", "RSTD", "Utility")),
lowers = list(c(0, 0), c(0, 0, 0), c(0, 0, 0)),
uppers = list(c(1, 5), c(1, 1, 5), c(1, 5, 1)),
control = list(core = 10, sample = 100, iter = 100)
)Recovery TD Simulating... Fitting TD |================== | 25%
3. Fit Real Data
A model that achieves good parameter recovery in Step 2 indicates that it has reliability. A model that achieves good model recovery in Step 2 indicates that it is distinguishable from other models.
Only models that possess both reliability and distinguishability should be used to fit real data. The optimal model is then determined based on how similar the experimental effects reproduced by the model are to those observed in human participants.
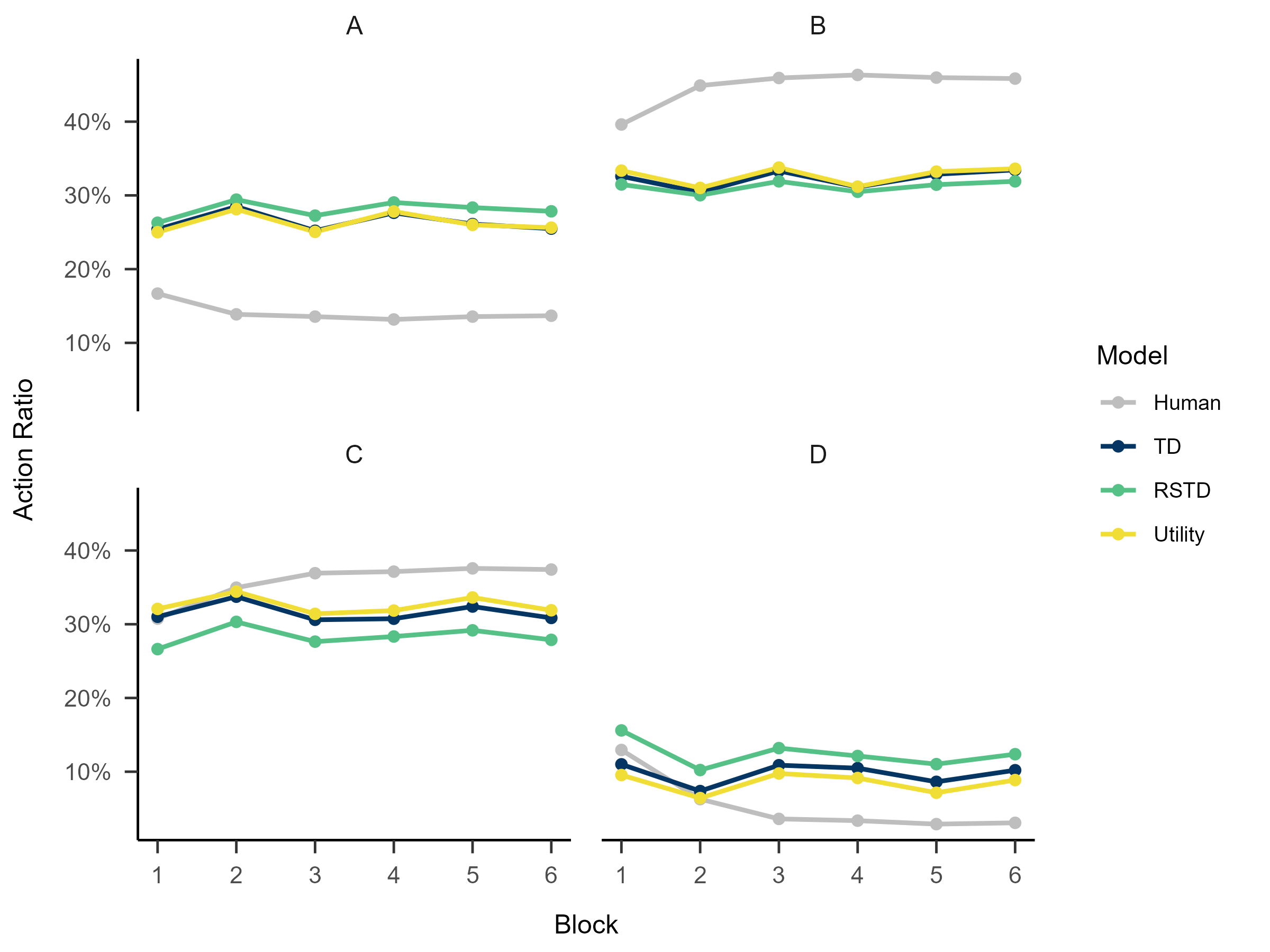
Note
It is crucial to identify an experimental effect plot with distinctive characteristics. The default plots, which display action ratios for each block, may fail to capture the subtle differences between models.
fitting.MLE <- multiRL::fit_p(
estimate = "MLE",
data = data,
colnames = colnames,
behrule = behrule,
models = list(multiRL::TD, multiRL::RSTD, multiRL::Utility),
settings = list(name = c("TD", "RSTD", "Utility")),
lowers = list(c(0, 0), c(0, 0, 0), c(0, 0, 0)),
uppers = list(c(1, 5), c(1, 1, 5), c(1, 5, 1)),
control = list(core = 10, iter = 100)
)Fitting TD |================== | 25%
4. Replay the Experiment
The results from recovery(rcv_d) and
fitting(fit_p) can be passed to the rpl_e
function to reproduce the behavioral patterns generated by
re-incorporating these parameters into the model.
Note
Since log-likelihood is basically a way of compressing data, you might want to try other estimation methods if it doesn’t give you acceptable parameter or model recovery.
replay.recovery <- multiRL::rpl_e(
result = recovery.MLE,
data = data,
colnames = colnames,
behrule = behrule,
models = list(multiRL::TD, multiRL::RSTD, multiRL::Utility),
settings = list(name = c("TD", "RSTD", "Utility")),
omit = c("data", "funcs")
)
plot(x = replay.recovery)



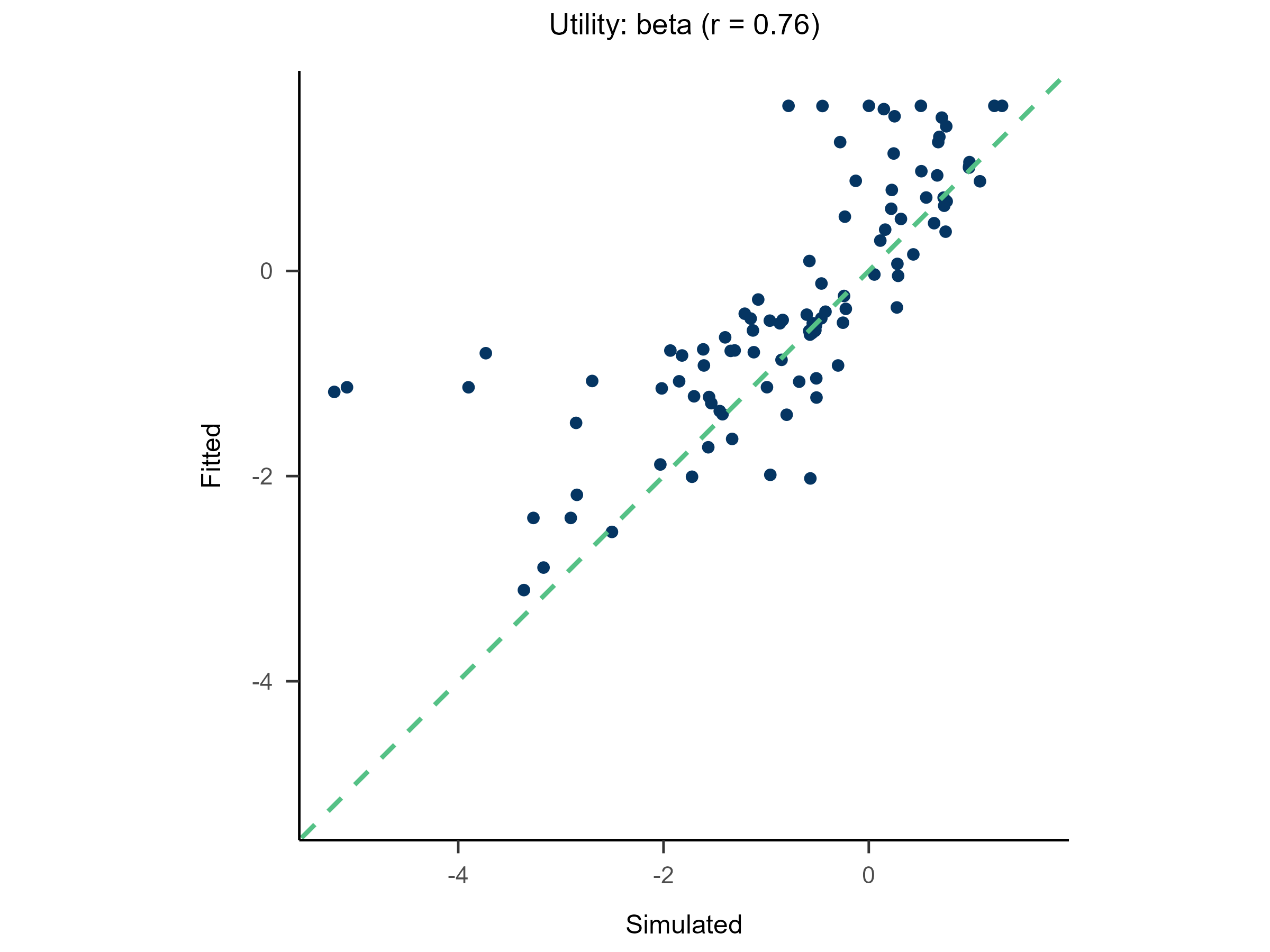

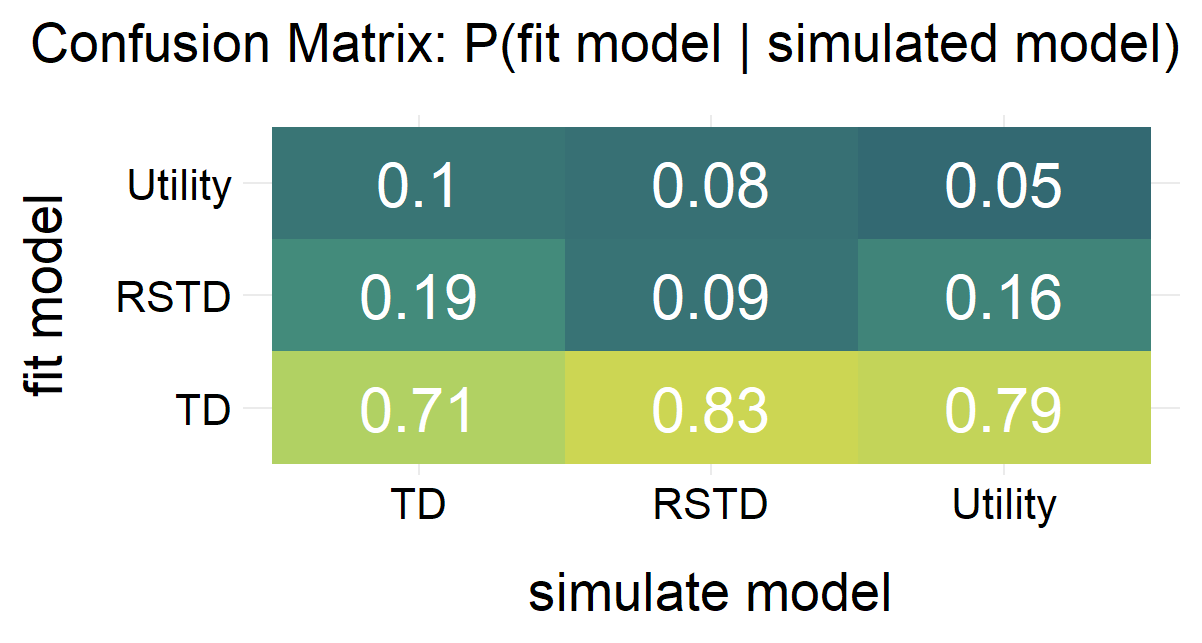
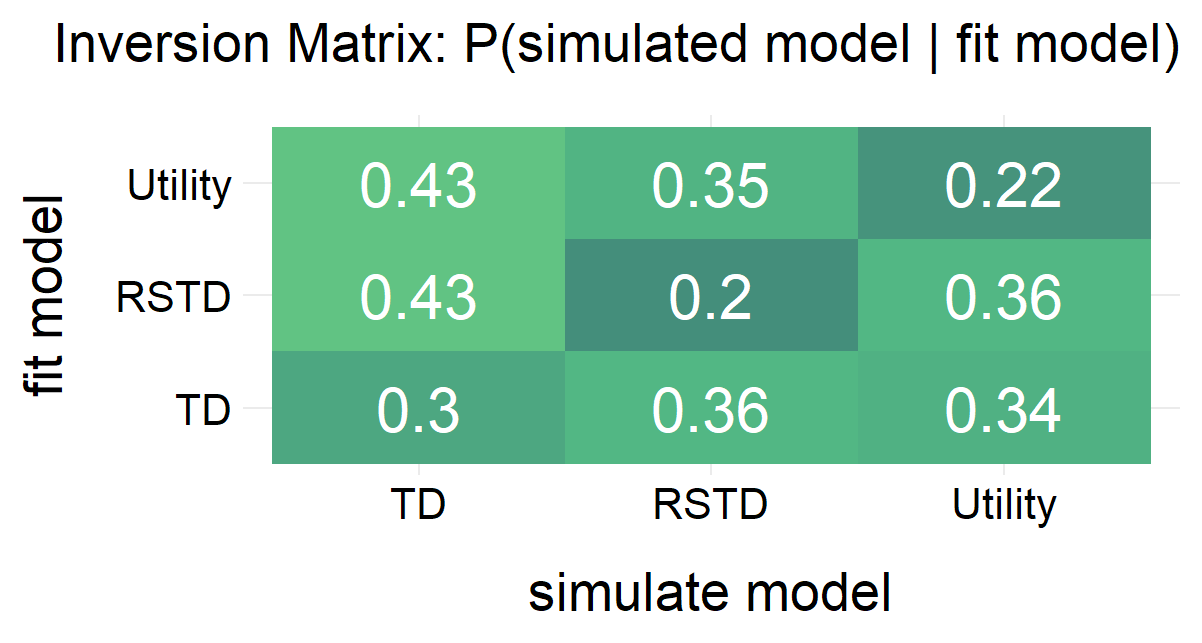
replay.fitting <- multiRL::rpl_e(
result = fitting.MLE,
data = data,
colnames = colnames,
behrule = behrule,
models = list(multiRL::TD, multiRL::RSTD, multiRL::Utility),
settings = list(name = c("TD", "RSTD", "Utility")),
omit = c("funcs")
)
plot(x = replay.fitting)